RunMongoAggregation
概述
按照设置的语句,访问mongodb运行聚合查询。语句里支持使用变量表达式和表达式计算。 MongoDB聚合查询语法可以参考官网:https://www.mongodb.com/blog/post/faceted-search-with-mongodb
属性说明
一般主要设置mongodb连接信息和查询的Collection名,其他属性可根据实际情况配置(查阅描述)。
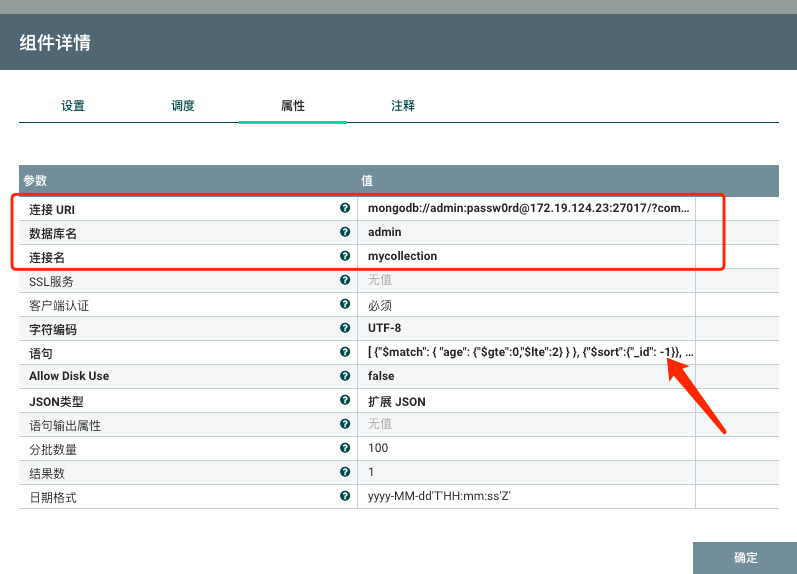
- 连接URI 比如: mongodb://admin:passw0rd@172.19.124.23:27017/?compressors=disabled&gssapiServiceName=mongodb
- 数据库名
- 连接名:也就是Collection名
- 语句: 用于执行聚合的语句
示例
###样本数据 假设我们有admin库的myCollection有如下内容:(动物名和年龄,这里忽略描述格式)
name=Dog,age=1;name=Cat,age=1; name=Rabbit,age=2;
name=Peppa,age=3;name=Pig,age=1; name=Tigger,age=2; name=Long,age=3
共7条动物数据。
示例1:聚合查询
流程说明
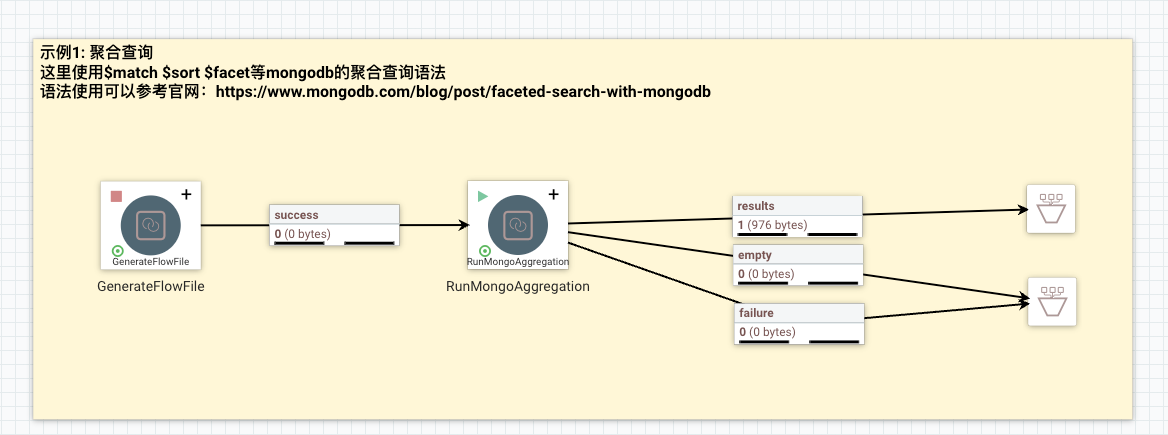
设置重要的连接信息
在语句中,使用mongodb的聚合查询语句,比如这里按_id降序排列且age满足:0<=age<=2。
[
{"$match": {
"age": {"$gte":0,"$lte":2}
}
},
{"$sort":{"_id": -1}},
{
"$facet": {
"data": [
]
}
}
]
执行结果
{
"data": [{
"_id": {
"timestamp": 1668482270,
"machineIdentifier": 5697997,
"processIdentifier": 16661,
"counter": 1749115,
"timeSecond": 1668482270,
"time": 1668482270000,
"date": 1668482270000
},
"name": "Tigger",
"age": 2
},
{
"_id": {
"timestamp": 1668482270,
"machineIdentifier": 5697997,
"processIdentifier": 16661,
"counter": 1749114,
"timeSecond": 1668482270,
"time": 1668482270000,
"date": 1668482270000
},
"name": "Pig",
"age": 1
},
{
"_id": {
"timestamp": 1668482270,
"machineIdentifier": 5697997,
"processIdentifier": 16661,
"counter": 1749112,
"timeSecond": 1668482270,
"time": 1668482270000,
"date": 1668482270000
},
"name": "Rabbit",
"age": 2
},
{
"_id": {
"timestamp": 1668482270,
"machineIdentifier": 5697997,
"processIdentifier": 16661,
"counter": 1749111,
"timeSecond": 1668482270,
"time": 1668482270000,
"date": 1668482270000
},
"name": "Cat",
"age": 1
},
{
"_id": {
"timestamp": 1668482270,
"machineIdentifier": 5697997,
"processIdentifier": 16661,
"counter": 1749110,
"timeSecond": 1668482270,
"time": 1668482270000,
"date": 1668482270000
},
"name": "Dog",
"age": 1
}
]
}
执行成功,路由到success线上。流文件内容按语句执行的聚合查询结果。共5条符合,按_id降序排列且age满足:0<=age<=2。
示例2:聚合查询实现数据分页
流程说明
实际生产中,很常见的场景是使用聚合查询的数据要求分页返回。可以引入变量和平台表达式计算方式,去灵活的计算取数据的范围。这个例子给出参考。
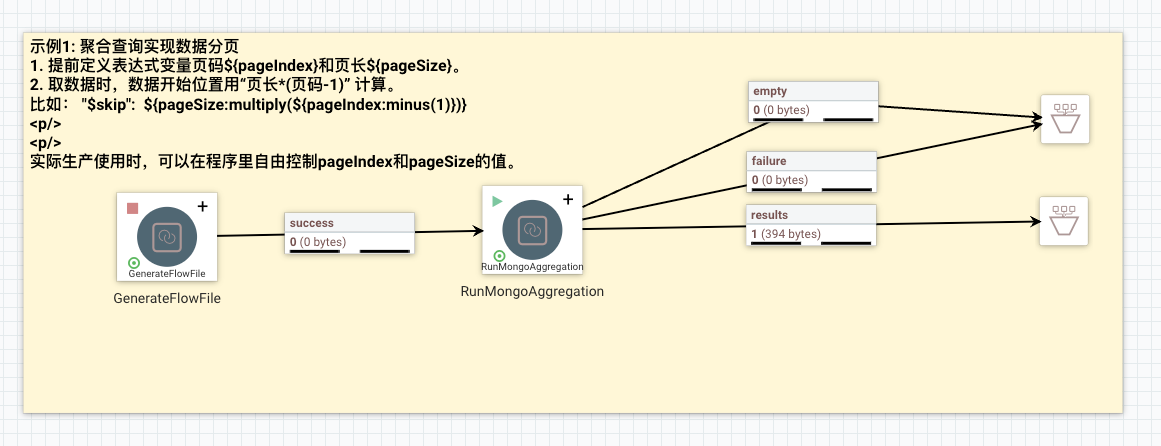
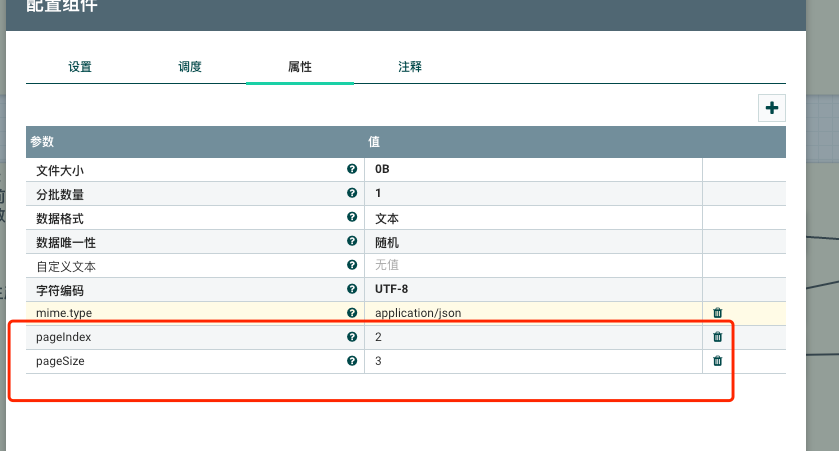
GenerateFlowFile里定义两个变量,页码pageIndex和页长pageSize。
RunMongoAggregation组件设置重要的连接信息,设置语句时可以结合mongodb的$skip和$limit的写法。
比如下面JSON的$skip和$limit的值的计算,取数据时,数据开始位置用“页长*(页码-1)” 计算。
[
{"$match": {
"age": {"$gte":0,"$lte":2}
}
},
{"$sort":{"_id": -1}},
{
"$facet": {
"data": [
{
"$skip": ${pageSize:multiply(${pageIndex:minus(1)})}
},
{
"$limit": ${pageSize}
}
]
}
}
]
执行结果
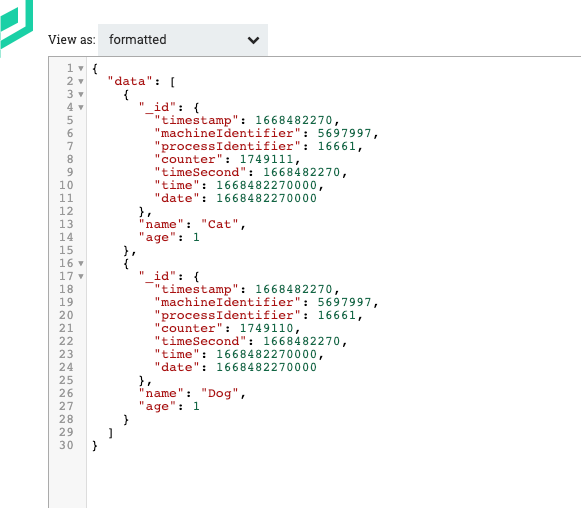
按照定义数据,这里取页码=2的数据,也就是第2页数据,因为页长pageSize是3。满足0<=age<=2共有数据是5条,第1页数据是3条,第2页数据是2条。这里返回2条。
{
"data": [
{
"_id": {
"timestamp": 1668482270,
"machineIdentifier": 5697997,
"processIdentifier": 16661,
"counter": 1749111,
"timeSecond": 1668482270,
"time": 1668482270000,
"date": 1668482270000
},
"name": "Cat",
"age": 1
},
{
"_id": {
"timestamp": 1668482270,
"machineIdentifier": 5697997,
"processIdentifier": 16661,
"counter": 1749110,
"timeSecond": 1668482270,
"time": 1668482270000,
"date": 1668482270000
},
"name": "Dog",
"age": 1
}
]
}
流程模板
参见附件(请右键另存保存):RunMongoAggregation示例