InferAvroSchema
根据JSON或CSV数据生产对应的AvroSchema
参数说明
Schema输出目的地
指定生成的AcroSchema的输出位置
- 数据流内容:将生成的Schema输出到数据流内容
- 数据流属性:将生成的Schema输出到数据流属性
输入内容类型
指定输入流文件内容的数据类型
CSV头部定义
当从CSV数据中提取AvroSchema时,需要设置CSV对应的列名称,以英文逗号分隔
从数据获取CSV头定义
设置该属性为true时,组件会试图从输入的流文件内容的第一行中读取CSV列名称
CSV头部跳过行数
指定读取CSV数据内容时从第几行开始,跳过前面部分,为0时代表读取全部内容
CSV分隔符
指定CSV记录的分隔符
CSV转义字符串
指定流文件中CSV的转移序列字符串
CSV引号字符串
指定流文件中CSV的引号字符串
格式化输出Avro
是否格式化输出AvroSchema
包含doc属性
指定输出的AvroSchema是否包含doc字段,一般设置为不包含,因为doc字段仅作为说明
Avro记录名称
指定输入的AvroSchema记录名,该字段必填
要分析的记录数量
指定JSON生产AvroSchema时采用多少条记录来检验,值越大则生成的结果越准确,一般来说设置为10足够了
字符编码
CSV数据的字符集编码
输出连线
- failure连线表示合并失败的数据流输出
- success连线表示合并成功的数据流输出
- original连线表示生成成功后原始的数据流输出
- unsupported content连线表示输入的数据类型不支持
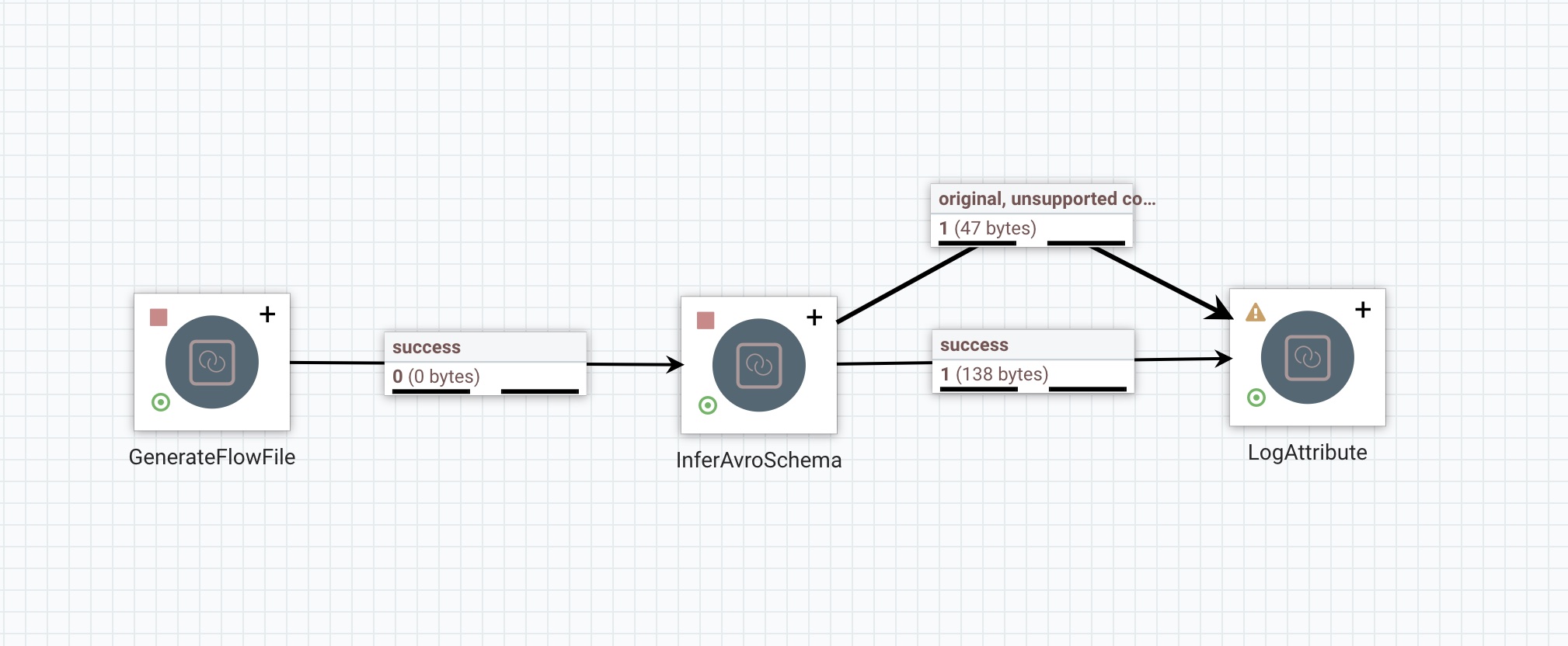
示例
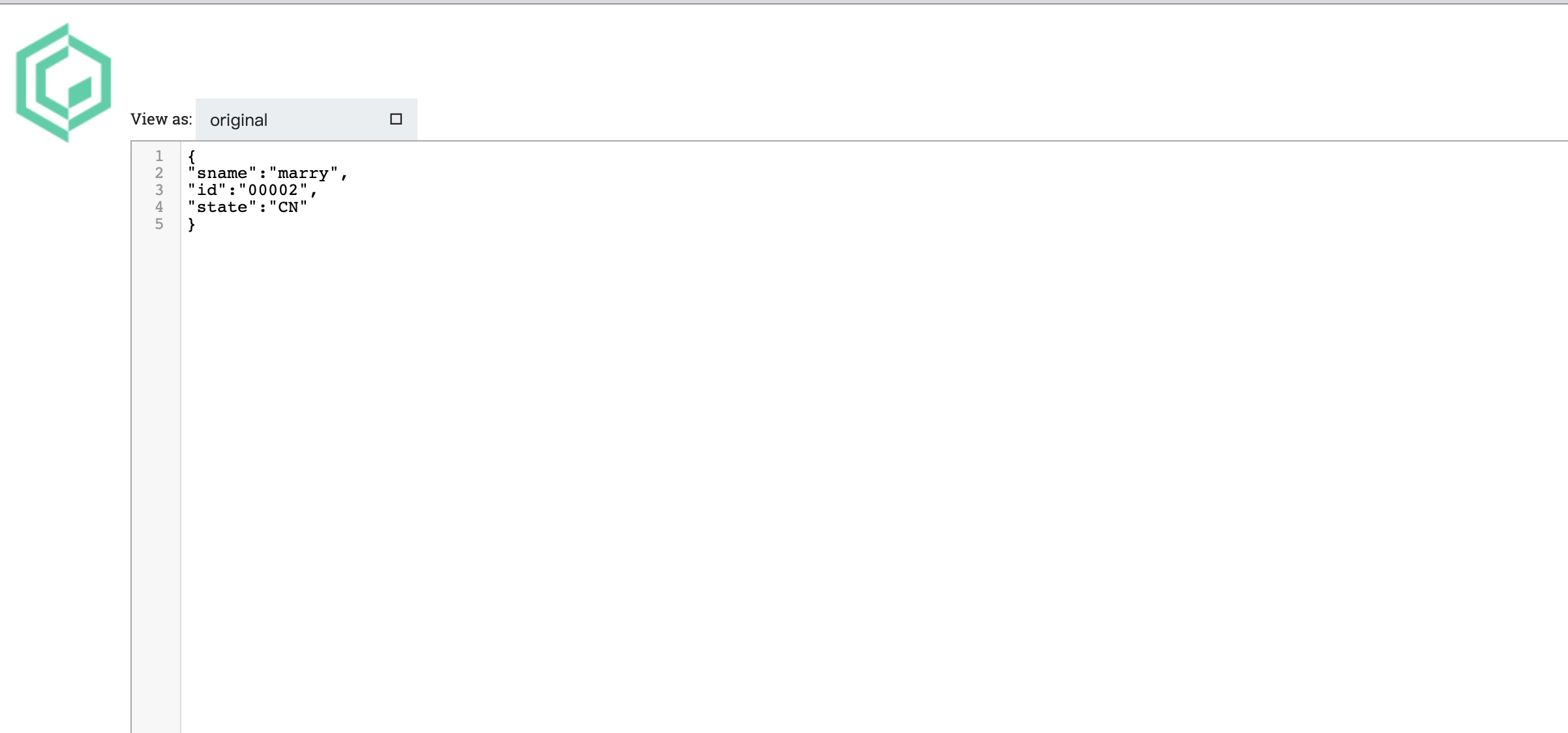
GenerateFlowFile配置
为避免生成过多数据,将组件”调度“中的”运行安排“设置为7 days。
再将”自定义文本“设置为:
{
"sname":"marry",
"id":"00002",
"state":"CN"
}
流程说明
在此流程中会生成其他控制器服务或组件可以直接使用的AvroSchema数据,需要注意,如果使用JSON数组来生成是,对生成结果需要进行修改才能在控制器服务或其他组件中使用
MergeContent设置
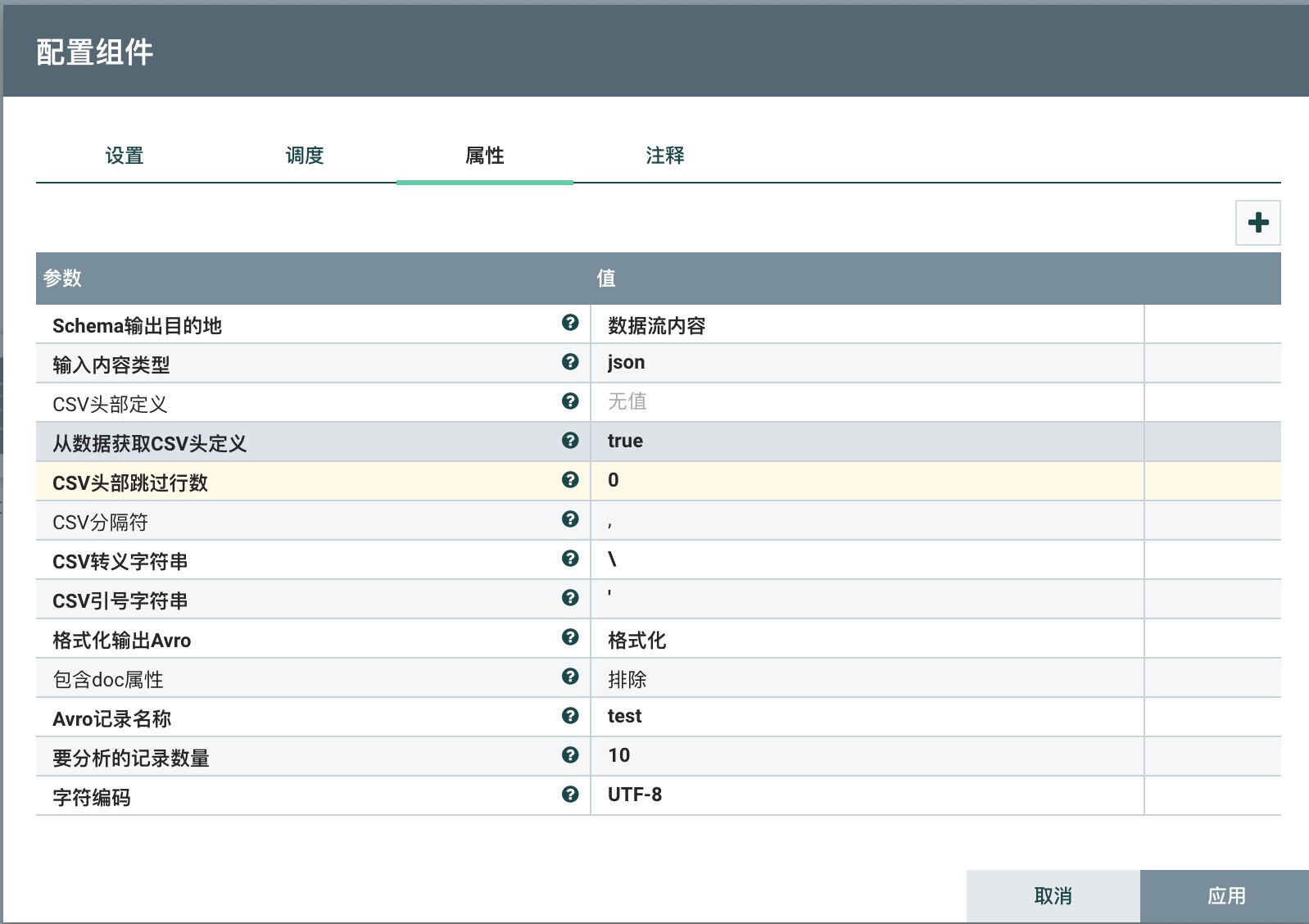
以合并JSON对象生成ArvoSchema为例,设置了Schema输出目的地为数据流内容,输入内容类型为Json,包含doc属性为排除,Avro记录名称为test,其余属性保持默认配置。
结果
最后输出结果如下:
- success连线输出结果

- original连线输出结果
流程模板
参见附件(请右键另存保存):模板文件