ExtractXMLToAttributes 提取匹配值
说明
通过提供动态参数配置,必须为XPath或XQuery表达式,根据匹配情况决定提取为相应的输出。
参数说明
- 递归子元素:当XPath或XQuery表达式计算所得为XML节点时,默认仅提取第一级的字段和值,而不递归处理子元素是复杂节点的情况。
- 允许数组:当XPath或XQuery表达式计算所得为数组时,是否提取数组中的对象并添加相应的序号来分别。
- 包含字段:当无
排除字段参数无指定时,如果不设置该参数,则默认包含全部表达式计算出的字段;否则仅包含指定的字段。支持正则表达式 - 排除字段:优先按该参数设置排除相应的字段。支持正则表达式。如果同时设置
包含字段,则可支持包含字段中设置大范围的正则,然后在排除字段中进行二次正则筛选。 - 字段名大小写敏感:用于
包含字段和排除字段参数设置的正则表达式中是否忽略大小敏感。 - 包含参数名:指定是否将动态参数名作为最终输出的提取属性名的一部分,还是仅做为属性提取标记用。如果提取值为字面值,而不是对象或数组,则强制使用动态参数名作为属性名输出。
- <动态参数>:通过提供动态参数,指定需要提取的元素名的XPath或XQuery表达式,支持标准的表达式。默认不提供任何动态参数,表示从根提取全部,对于XPath 为”ALL = /*“, XQuery 为“ALL = for $elem in root() return $elem ”
示例说明
样本XML
<?xml version="1.0" encoding="UTF-8"?>
<Data xmlns="https://www.baishan.com">
<name>数聚蜂巢</name>
<age>3</age>
<site>https://www.baishan.com/tech/orchsym</site>
<details>
<address>
<city>北京</city>
<country>中国</country>
<street>望京</street>
<build floor="5" number="201" />
</address>
<post>100000</post>
<tel>010-12345678</tel>
<tags index="1" name="data">Data</tags>
<tags index="2" name="integration">Integration</tags>
<tags index="3" name="api">API</tags>
</details>
<links index="1">
<name flag="x">白山云</name>
<url>http://www.baishan.com</url>
</links>
<links index="2">
<name flag="y">白山云</name>
<url>http://www.baishancloud.com</url>
</links>
<links index="3">
<name flag="z">Orchsym</name>
<url>https://www.baishan.com/tech/orchsym/</url>
</links>
</Data>
XPath 根提取
不修改任何参数设置的前提下,也不指定表达式的动态参数,则默认为参数名ALL,值为 /*。
如需修改参数名,则需要显式指定,比如参数名为 data。
仅提取第一级字段
仅提取第一级字段并添加了设置字段过滤。
参数设置

- 包含字段: 设置了正则表达式
"(.*)a(.*)",表示仅提取包含a字母的字段。 - 其他默认值。
由于未设置递归子元素,则仅提取第一级的字段为属性。
结果

由于默认的动态参数表达式为”ALL = /*“, 则提取到的属性为 ”ALL.age“ 和 ”ALL.name“, 其他为组件内置属性。
可以看出,相应提取后的结果仅包含”name“ 和 ”age“,而排除了 ”site“字段:
ALL.name = 数聚蜂巢
ALL.age = 3
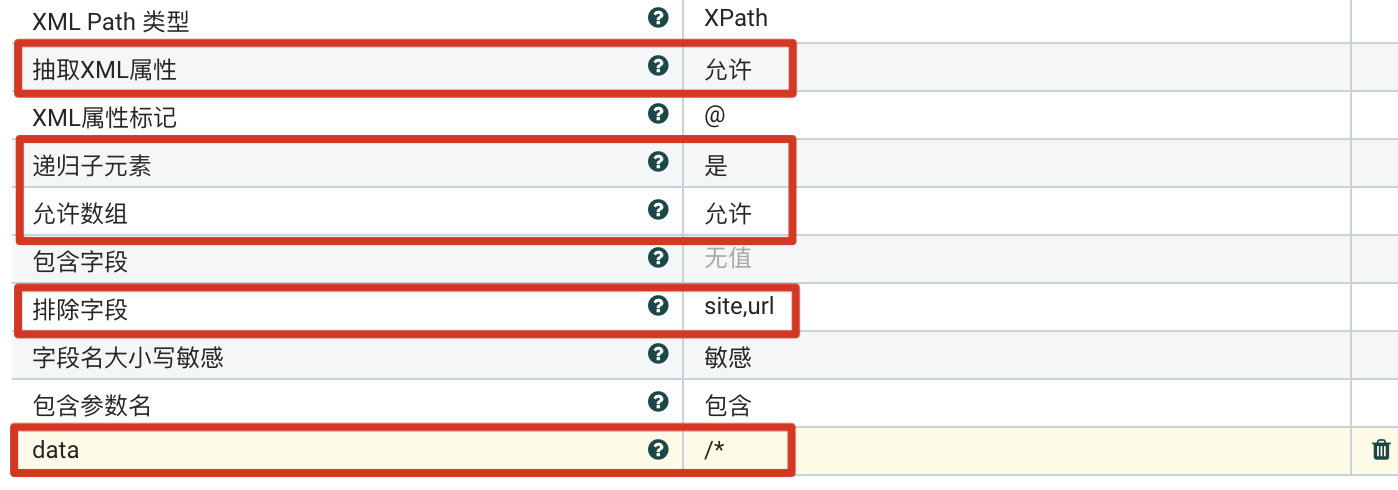
支持子元素、数组、包含参数名
设置可递归子元素,支持数组值提取,以及自定义了动态参数名,并将值为URL的字段排除掉。
参数设置
- 抽取XML属性 设置为允许
- 递归子元素 设置为允许。
- 允许数组:设置为支持。
- 排除字段:排除值是URL的字段,”site“和”url“。
- <动态参数>:设置动态参数名为”data“,避免默认的内嵌动态参数名”ALL“。
结果

所有属性均以动态参数名”data“为开头,并成功提取到了子元素和数组字段:
data.@xmlns = https://www.baishan.com
data.name = 数聚蜂巢
data.age = 3
data.details.address.build =
data.details.address.build.@floor = 5
data.details.address.build.@number = 201
data.details.address.city = 北京
data.details.address.country = 中国
data.details.address.street = 望京
data.details.post = 100000
data.details.tel = 010-12345678
data.details.tags.0 = Data
data.details.tags.@index.0 = 1
data.details.tags.@name.0 = data
data.details.tags.1 = Integration
data.details.tags.@index.1 = 2
data.details.tags.@name.1 = integration
data.details.tags.2 = API
data.details.tags.@index.2 = 3
data.details.tags.@name.2 = api
data.links.@index.0 = 1
data.links.name.0 = 白山云
data.links.name.@flag.0 = x
data.links.@index.1 = 2
data.links.name.1 = 白山云
data.links.name.@flag.1 = y
data.links.@index.2 = 3
data.links.name.2 = Orchsym
data.links.name.@flag.2 = z
则所有属性将被提取到属性,默认为包含"@"开头的字段名组成的属性。
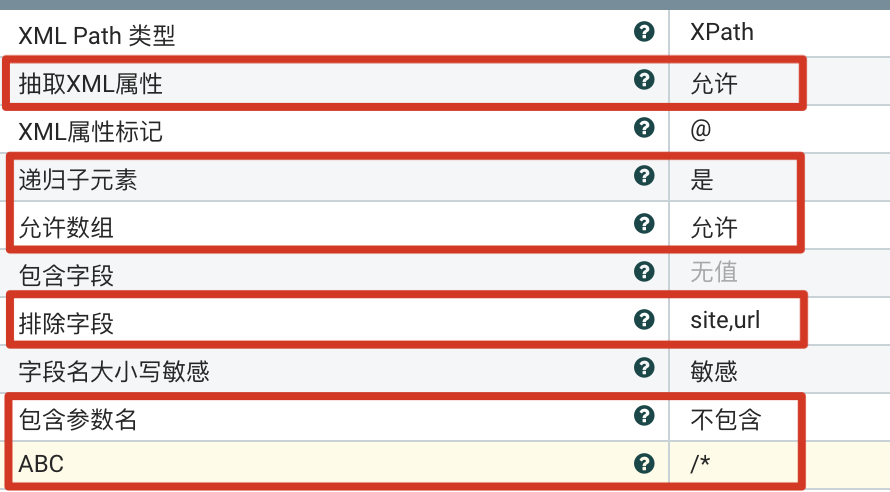
支持子元素、数组、不包含参数名
设置可递归子元素,支持数组值提取,还将值为URL的字段排除掉,并设置不包含参数名,所以动态参数名社资格可任意。
参数设置
- 递归子元素 设置为允许。
- 允许数组:设置为支持。
- 排除字段:排除值是URL的字段,”site“和”url“。
- 包含参数名:设置为不包含。
- <动态参数>:设置动态参数名为”ABC“,由于表达式为
”/*“,且不包含参数名,计算出的结果为对象,则参数名始终被忽略掉。
结果
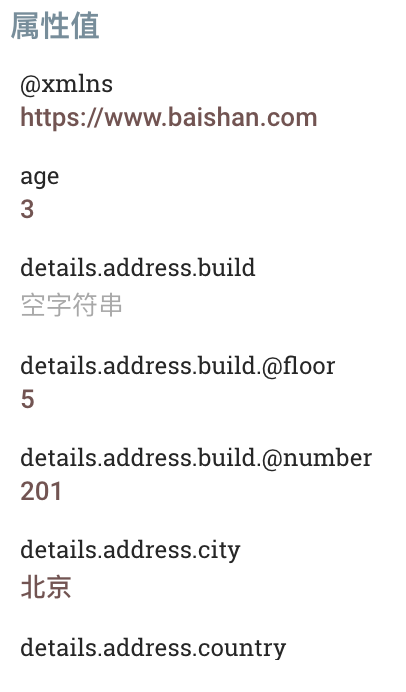
所有属性仅保留字段作为属性名,并成功提取到了子元素和数组字段:
@xmlns = https://www.baishan.com
name = 数聚蜂巢
age = 3
details.address.build =
details.address.build.@floor = 5
details.address.build.@number = 201
details.address.city = 北京
details.address.country = 中国
details.address.street = 望京
details.post = 100000
details.tel = 010-12345678
details.tags.0 = Data
details.tags.@index.0 = 1
details.tags.@name.0 = data
details.tags.1 = Integration
details.tags.@index.1 = 2
details.tags.@name.1 = integration
details.tags.2 = API
details.tags.@index.2 = 3
details.tags.@name.2 = api
links.@index.0 = 1
links.name.0 = 白山云
links.name.@flag.0 = x
links.@index.1 = 2
links.name.1 = 白山云
links.name.@flag.1 = y
links.@index.2 = 3
links.name.2 = Orchsym
links.name.@flag.2 = z
表达式提取
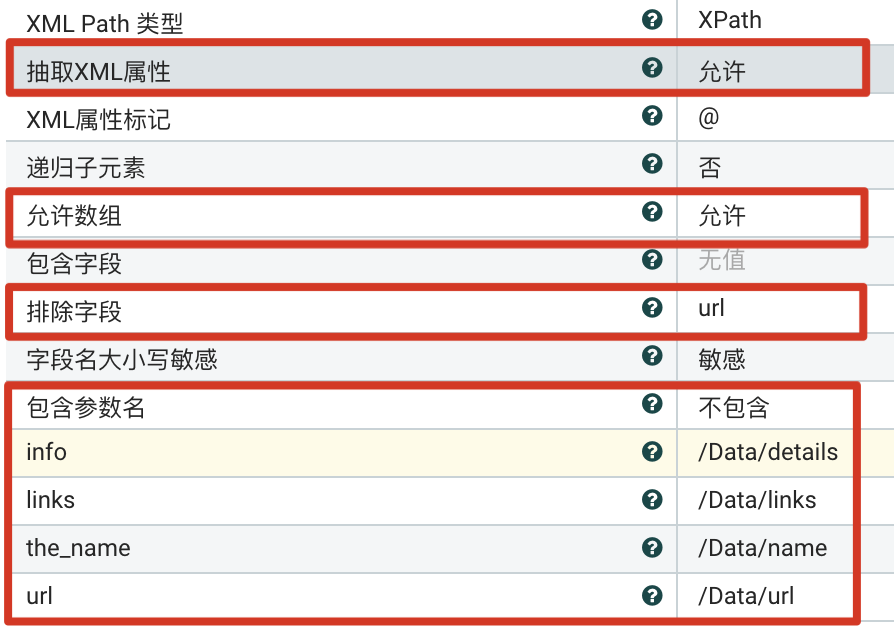
支持数组、不包含参数名
显式指定提取部分字段的多个动态参数和XPath表达式。
参数设置
- 递归子元素 设置为允许。
- 允许数组:设置为支持。
- 排除字段:排除值是URL的字段,”url“。
- 包含参数名:设置为不包含。
- <动态参数>:设置4个动态参数,比如”the_name“与原名字不同,”links“指向数组。
结果

对于字面值的提取,提取后的属性以动态参数的名字作为新属性名,比如”the_name“:
the_name = 数聚蜂巢
url =
post = 100000
tel = 010-12345678
tags.0 = Data
tags.@index.0 = 1
tags.@name.0 = data
tags.1 = Integration
tags.@index.1 = 2
tags.@name.1 = integration
tags.2 = API
tags.@index.2 = 3
tags.@name.2 = api@index.0 = 1
@index.1 = 2
@index.2 = 3
name.0 = 白山云
name.@flag.0 = x
name.1 = 白山云
name.@flag.1 = y
name.2 = Orchsym
name.@flag.2 = z
其中,由于”url“指定的JSON Path表达式没有对应的值,所以为空字符串。
支持子元素、数组、不包含参数名
显式指定提取部分字段的多个动态参数和XPath表达式。
参数设置
- 递归子元素 设置为允许。
- 允许数组:设置为支持。
- 排除字段:排除值是URL的字段,”url“。
- 包含参数名:设置为不包含。
- <动态参数>:设置动态参数,比如”the_name“与原名字不同,”links“指向数组。
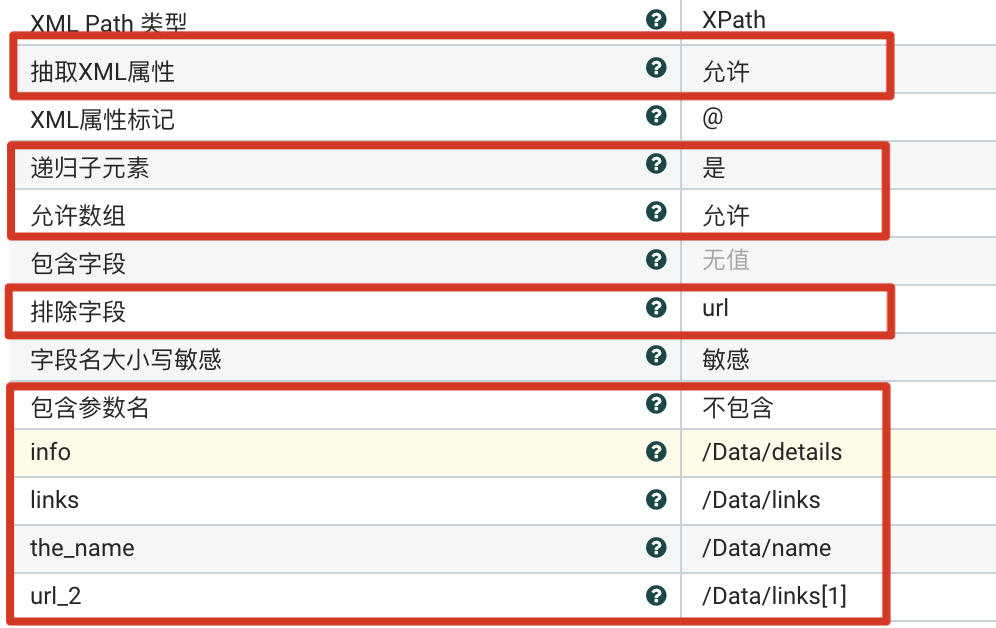
结果

对于字面值的提取,提取后的属性以动态参数的名字作为新属性名,比如”the_name“:
the_name = 数聚蜂巢
@index = 1
@index.0 = 1
@index.1 = 2
@index.2 = 3
address.build =
address.build.@floor = 5
address.build.@number = 201
address.city = 北京
address.country = 中国
address.street = 望京
post = 100000
tel = 010-12345678
tags.0 = Data
tags.1 = Integration
tags.2 = API
tags.@index.0 = 1
tags.@index.1 = 2
tags.@index.2 = 3
tags.@name.0 = data
tags.@name.1 = integration
tags.@name.2 = api
name.0 = 白山云
name.1 = 白山云
name.2 = Orchsym
name.@flag = x
name.@flag.0 = x
name.@flag.1 = y
name.@flag.2 = z
数组序号引用
通过指定XML元素的序号的XPath表达式来提取属性。
参数设置
- 允许数组:设置为支持。
- 排除字段:排除值是URL的字段,”name“。
- 包含参数名:设置为不包含。
- <动态参数>:设置动态参数,指定数组序号的XPath。
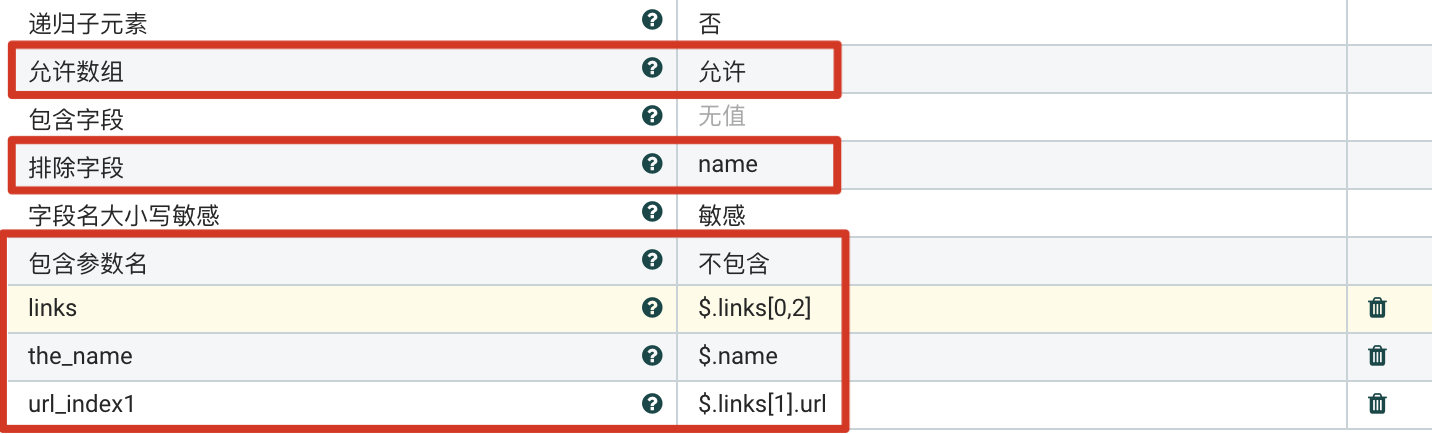
结果

对于字面值的提取,提取后的属性以动态参数的名字作为新属性名,比如”url_index1“:
@index = 2
@index.0 = 1
@index.1 = 3
url.0 = http://www.baishan.com
url.1 = https://www.baishan.com/tech/orchsym/
url = http://www.baishancloud.com
由于排除了”name“字段,尽管设置了”the_name“,但被过滤掉,并且”links“下的”name“字段也被过滤掉。
注意: ”url.1“实际上是第三个,由于该索引序号是由结果而来,无从指定原始JSON中的索引序号,所以是序号1,是依据结果进行排序。
简单类型数组引用
参数设置
- 允许数组:设置为支持。
- 包含参数名:设置为不包含。
- <动态参数>:设置动态参数,仅指定简单类型数组。

结果

the_tag.0 = Data
the_tag.0.@index = 1
the_tag.0.@name = data
the_tag.1 = Integration
the_tag.1.@index = 2
the_tag.1.@name = integration
the_tag.2 = API
the_tag.2.@index = 3
the_tag.2.@name = api
由于动态参数指定的是数组,如果参数不支持数组,则没有任何属性结果。
流程模板
参见附件(请右键另存保存):XPath提取属性模板